Decoding LLDP and CDP packets using a TLV reader for C++
Further to my previous post, this post details how to interpret network discovery packets – LLDP and CDP – that have been captured on a network interface. To do this, I’ll explain how to create a Type, Length and Value reader that reads an array of characters, determines the type of packet and its subsequent data fields and then outputs those values to a console window.
This posts follows on from that previous one, but you won’t be using any WinPcap functions anymore. In fact, all you need is an array of chars to work with, since that is what will have been captured already.
Find out what the packet type is
The first time I tried to do this, I didn’t bother with working out where TLVs were at all. I simply relied on trying to work out which bytes would probably have which bits of data (this is true, also, of how I treated CDP packets) as I mentioned previously. Essentially, I looked at packets that had been captured with Wireshark – but the output varied between PCs, which ultimately depended on which optional data is included.
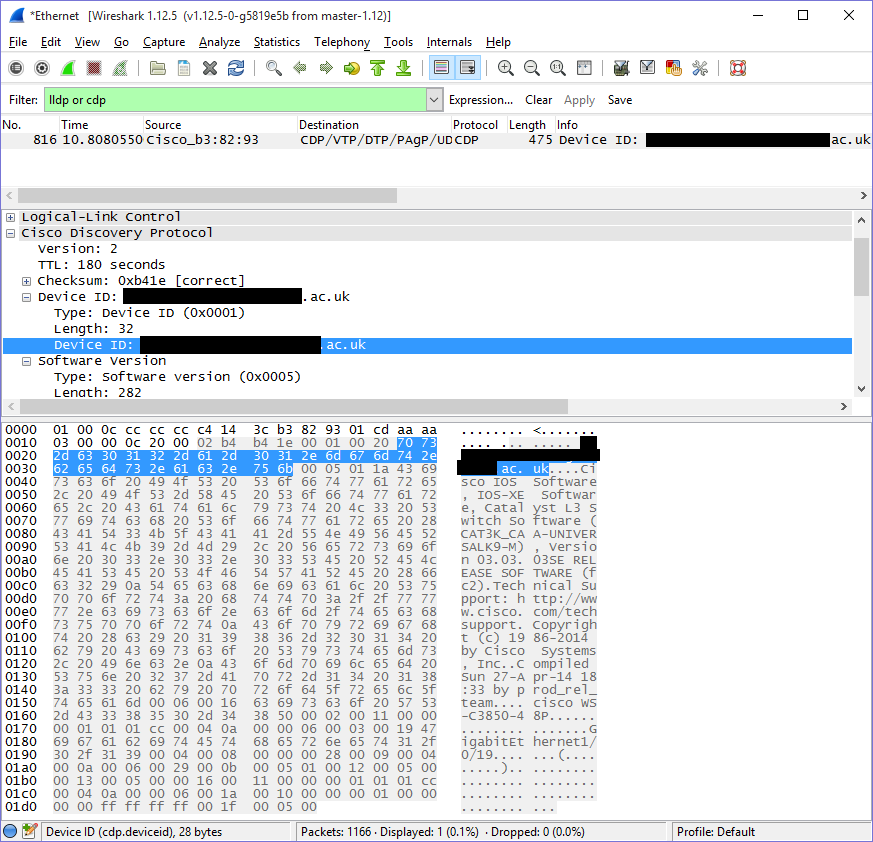
This is still very helpful with knowing which values I should expect, however. You can work out which parts of a packet correspond to which fields by selecting them in the middle pane. So its doing the same kind of thing we’re trying to do anyway; read a list of packets that have been captured on an interface and display them in a human-readable way. However, we’re just doing a very specific and chopped down form of this.
The first thing to do is to determine which packet was received on the interface. We already know it will be a CDP or LLDP packet, so an easy way to determine the type is to just check to see if it is one of them.
int testPacketType = (packetData[12] << 8 | packetData[13]);
if (testPacketType == 0x88cc)
{
getDataLLDP();
}
else
{
getDataCDP();
}
Because a packet’s type is represented over two bytes, we can “push” two bytes into one variable with the << operator. This will perform a bitshift on packetData[12], moving it by 8 places as specified, and add it together with packetData[13] before finally storing it in a two-byte variable; a standard int. Its worth mentioning that they don’t actually get added at all – both bytes gets logically or‘d, which results in all 16 bits being populated. Represented as a numerical value, you would see this as 35020 – the hexadecimal form is, therefore, 88cc.
If the value is different, then it must be a CDP packet instead. Either way, we will direct the packet to one of two functions; getDataLLDP() or getDataCDP(). Both packets are very similar in that the first 12 bytes are a destination and source address, followed by several blocks of data, spaced out by a length and identified by a type. Both protocols are also defined in their relevant specifications, which helps immensely with knowing what data you should be trying to read (int or char? single- or multi-byte values, or sub-byte values?)
Reading an LLDP packet
Aside from one error, which you can find at the end of this article, you can get all the TLV information you need from the IEEE 802.1AB-2009 specification. It says exactly what format the data should be in and how the TLVs should be formed. Since we are only reading – rather than forming or transmitting – a packet, we can get away with interpreting things in a way that’s easiest for us. Nevertheless, we still have to read all of the TLVs, because they are sequential and rely on the previous TLV to determine where exactly they start from.
- To begin with, we can get the MAC addresses out of the way.
- We know that bytes 13 and 14 (which are 12 and 13) are going to represent the type as LLDP already, so we can ignore them.
- Anything else is going to be data, represented as TLVs. Now we can start running a count, because as we traverse the packet, we want to make sure we know where we are up to!
void getDataLLDP()
{
printf("\tDestination MAC address:\t %02x:%02x:%02x:%02x:%02x:%02x", packetData[0], packetData[1], packetData[2], packetData[3], packetData[4], packetData[5]);
printf("\n\tSource MAC address:\t\t %02x:%02x:%02x:%02x:%02x:%02x", packetData[6], packetData[7], packetData[8], packetData[9], packetData[10], packetData[11]);
printf("\n\tContents: ");
unsigned int count = 14;
...
So far so good. Notice how you reference data in a packet? You simply say packetData[x], where x is the specific byte you want to read. Then you can format it as a hexadecimal character (formatting the output with %x, or %02x to ensure that you pad it out with up to two hexadecimal 0s, to make it look like a proper MAC address), character (%c) or anything else you might want.
Things get a bit more involved when you don’t work with whole bytes. With an LLDP TLV, the first two bytes represent “type” and “length”, with all subsequent bytes being the value (for as long as specified by, of course, the length). So look at this simple diagram below of how you would think a TLV should look, with regards to how the bytes represent “type” and “length” data:
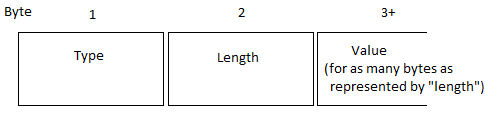
..and then forget it again, because it actually looks like this:
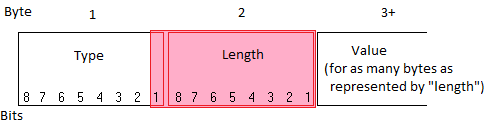
Instead of having one byte for the length, it has 9 bits; 1-and-a-bit bytes. So the type is actually only 7 bits. Looks like we have to do some more bit-shift magic to make things work how we want them to. Make a for loop as below, although this one may as well be a while loop, since we aren’t initialising or doing any logic in the statement other than checking to see if count is less than the length of the packet’s header (this stops us starting to read beyond the end of the packet).
...
int mask = 0x01FF;
for (; count < packetHeader->len; )
{
unsigned char type = (packetData[count] >> 1);
unsigned int length = (packetData[count] << 8 | packetData[count + 1]);
length &= mask;
count += 2;
...
The first thing we do is get the type. To do this, we copy the value from the first byte into a single byte type (e.g. a char), but this time we bit shift to the right. This means we lose the first bit of data; but that’s fine, because it didn’t belong to this anyway. Now, all the bits have shifted to their correct position (although we could probably have just divided everything by two and got the same result, because this is how you’d perform a division operation in binary anyway).
The next thing to do is to get the length. This time, we need two bytes to store the value in, so we can use an int (note how both of these are unsigned – this is to prevent values being read as negative by accident, indicated by the left-most bit). We can store both bytes’ values in here like we did earlier, when trying to see if the packet was LLDP or CDP, although this time, we want to remove 7 of the 8 bits. To do this, we can use a mask; so you could either minus 65024 from the final value, which represents 11111110 0000000, or we could perform a bit more maths by anding. 0x01FF represents the bits we want to keep – so performing an and will preserve only the bits we want.
Finally, we need to get the value. A few things to mention first:
- As I stated earlier, the IEEE specs specify what values to expect for a given “type”.
- So, starting two bytes after the type and length have been specified, we can read length amount of bytes into the packet where we can then expect the next type and length to be specified.
- In this way, we can know exactly how many fields there are, what fields there are and how big they are.
- The IEEE specification is also useful in knowing how to format a specific TLV; sometimes, there are subtypes, sometimes the value is hexadecimal, somethings it is text data.
- There are specific TLVs that must always be included that you can expect to be present; “Chassis ID”, “Port ID”, “Time-to-Live” and a terminating TLV that basically indicates that this is the end of the packet (You can find more info about this in section 9.1 of the 2005 specification)
- There are optional TLVs that might also be included, too, as well as organisationally-specific TLVs that may or may not be included
Luckily, it looks as though the specs are quite well-known and easy to get ahold of. With that out of the way, I will give an example of how you can implement this. So, straight after you have got the type and length, you can check what the type is:
unsigned char value[512] = "";
switch (type)
{
case 1:
{
printf("\nChassis ID:");
int subtype = packetData[count];
count += 1;
length -= 1;
if (subtype == 4)
{
printf("\n\tMAC address: %02x:%02x:%02x:%02x:%02x:%02x", packetData[count], packetData[count + 1], packetData[count + 2], packetData[count + 3], packetData[count + 4], packetData[count + 5]);
count += 6;
}
if (subtype == 6)
{
printf("\n\tInterface name:");
for (UINT16 x = 0; x < length; x++)
{
value[x] = packetData[count];
count++;
}
}
break;
}
}
First of all, we make a new character array to hold the value of the current TLV, up to the maximum value that we would expect (and length cannot exceed 512).
Next, we examine the type. From the specs, we know that a type of 1 is “Chassis ID” and that it also contains a subtype. I’m only going to list handling for two subtypes here; an interface name and a MAC address, since these are what seem to be the most often used values that I have seen so far. However, for a more complete implementation, you’ll want to include code to capture all conditions. Important: in the way this has been implemented, after you process a character, you must remember to increase the count. This tells you how many characters have been processed so far, which tells you where you should be along the packet. At the same time, the length is decreased by one when we know the subtype, because length is later used as a measurement of how many characters should be printed out from the position indicated by count.
I will probably publish a more full implementation for handling LLDP packets at a later date, but one thing that I included, regardless, was a default case for anything that I haven’t written an implementation for. What it does is to simply attempt to print out the value of a given TLV as a string of characters.
default:
{
printf("\nUnimplemented type");
for (UINT16 x = 0; x < length; x++)
{
value[x] = packetData[count];
count++;
}
printf("\n\t%s", value);
break;
}
Reading a CDP packet
Cisco don’t seem to be as obliging on the specifications front; trying to find anything will return nothing nearly as useful as the IEEE specs for LLDP. There seem to be a few references to now-defuct links to useful links that no longer exist. You can probably find the right TLVs and formats from various open-source projects, but I really wanted to find something I could reference that was a bit more “official”.
As with LLDP, my first stop was to look at the CDP entry over on the Wireshark site. It seems that the relevant information on CDP packet information could once have been viewed here and here – however, these now redirect to fairly useless pages on how to configure switches, instead (and the second link, from what I can find on archive.org, doesn’t seem to have been much help in the first place for this).
Eventually, however, I managed to find a mirror of the first link amongst the bountiful wilderness of the internet, on some obscure Ukrainian site. The document appears to be titled “Catalyst Token Ring Switching Implementation Guide”, but the format of CDP remains the same since it is encapsulated within the media access specific gubbins. Combined with a few other useful links, as well as a few packet captures, I worked out what the various TLVs should be.
Thankfully, Cisco are more sensible with how they allocate bytes and decided that they’d give two bytes to length and two to value. There are also no organisation-specific TLVs, either, so the list is quite short.
- As with LLDP, we can get the MAC addresses out of the way.
- There’s then a load of useless stuff to us
- Bytes 20 and 21 are the protocol ID, which is how we knew this was CDP in the first place. 22, 23, 24 and 25 are more stuff we don’t need.
- Anything beyond byte 26 will be TLV data, as with LLDP
void getDataCDP()
{
printf("\tDestination MAC address:\t %02x:%02x:%02x:%02x:%02x:%02x", packetData[0], packetData[1], packetData[2], packetData[3], packetData[4], packetData[5]);
printf("\n\tSource MAC address:\t\t %02x:%02x:%02x:%02x:%02x:%02x", packetData[6], packetData[7], packetData[8], packetData[9], packetData[10], packetData[11]);
unsigned int count = 26;
Maybe the first thing to explain is why so many bytes pass, compared to LLDP, before you get any data. CDP is encapsulated in an Ethernet frame, rather than Ethernet 2 (and you can tell the difference because the length field of an Ethernet frame can’t exceed 1536, so if it does, it becomes an Ethernet II frame and represents type instead), with 802.2 LLC and SNAP headers. 8 bytes following the length in bytes 12 and 13, which contains LLC information for 3 bytes, the OUI for 3 bytes and then the protocol ID for the next two. Finally, bytes 24 and 25 are the checksum.
...
for (; count < packetHeader->len; )
{
unsigned int type = (packetData[count] <<8 | packetData[count + 1]);
unsigned int length = (packetData[count + 2] <<8 | packetData[count + 3]);
count += 4;
length -= 4;
unsigned char value[512] = "";
Although the above is very similar to the LLDP code, its worth noting that, unlike LLDP, the length of a TLV indicates total length of the CDP, including the length and type, rather than just the length of the data that follows; hence removing 4 from the length, whilst adding 4 to the count. Also note that bit shift operations are applied to both the type and length to place them both into integers.
switch (type)
{
case 0x01 :
{
printf("\n\tDevice ID: ");
break;
}
default :
{
break;
}
}
for (UINT16 x = 0; x < length; x++)
{
value[x] = packetData[count];
count++;
}
printf("%s", value, count - length);
What I’ve done here is to really simplify things by only making the switch statement determine what label the TLV is given and – regardless of type – handle every TLV as a string of characters. In the document I found, only a few TLVs were specified – however, Wireshark’s source code provides a much better insight into the types you can expect to see (no idea where they were originally sourced).
So it looks like there are almost 32 different TLVs that could be included in a CDP packet. However, not all of them read directly as strings of characters and do need additional formatting. With what I have posted here, you should be able to do some digging and work out how they need to be formatted, but I will post the full implementation at a future date.
Here’s one example; the second TLV type is addresses, which can contain more than one address, specified in the first four bytes. To get that, we just do some bit shifting (24, 16 and 8 bits) and then loop through that value for the rest of the TLV. Again, this only breaks down one address – I may well paste a more full implementation later.
case 0x02 :
{
printf("\n\n\tAddress: ");
long numberOfAddresses = (packetData[count] << 24 | packetData[count] << 16 | packetData[count + 2] << 8 | packetData[count + 3]);
count += 4;
length -= 4;
for (UINT16 x = 0; x < numberOfAddresses; x++)
{
count += 2;
//This is an IP address
if (packetData[count] == 0xcc)
{
printf("IP Address: ");
count++;
int addressLength = ( packetData[count] << 8 | packetData[count + 1]);
count += 2;
printf_s("%i.%i.%i.%i", packetData[count], packetData[count + 1], packetData[count + 2], packetData[count + 3]);
count += addressLength;
}
}
break;
}
.
Conclusion
There are a number of implementations of ways to read the LLDP and CDP TLVs already in existence in open-source projects and you will find that there are some common ways in which they’ve been implemented: for example, a nice way to handle LLDP TLVs can be found in tcpdump, an implementation of which can be foundover on github or on Apple’s open source repository. Another good project I found was The Assimilation Project, that has a good implementation of both CDP and LLDP packet handlers (not just the CDP information which I linked to). These applications all give nice structures for the names of the TLVs and subtypes and can save a lot of time in formatting things. However, they may be too cumbersome for certain applications, especially if you don’t need to actually print out the data and, instead, just want to pass it on to something else.
Whilst finding out information about how to capture CDP and LLDP data in the first place, I came across a number of blog posts that simply use command-line tcpdump/windump. The amount of sources that have delved deeper into actually pulling apart these packets seems to be a lot less numerous; so hopefully someone will come across this post and find it of use. Let me know if it is and if you have any questions!
Final note – wrong IEEE specs?
Its worth pointing out that the IEEE 802.1AB-2009 specification is wrong for part of this. It suggests that – for a “System Capabilities” TLV – the third byte is going to represent the “Chassis ID subtype”, for some unknown and bizarre reason. It is as though they’ve copy-pasted it from another one – Chassis ID in section 8.5.2 (page 26).
The previous spec, 802.1AB-2005, however, has the correct TLV format listed for a “System Capabilities” TLV on 9.5.8 (Page 26). It looks like they’ve realised this already but, hey, why bother taking down a 6 year old standard when its been up all that time harmlessly – its not like anyone is going to even read the document ever, right?
‹ Capturing LLDP and CDP packets using C++ and WinPcap Uploading data to a webserver Part 1 – C/C++ and CURL ›