FOG Update – Part 7
Further to the previous post, everything seems to have been a success. I wiped out list of hosts from the FOG database when I installed the server from scratch and so have been going around all of our PCs re-registering them all from the FOG host registration menu, using some sort of naming convention (<department><room>-<assettag>). As they are already all on Active Directory, the FOG script to join them (which initially didn’t work, see the previous post!) to AD sets them back into their groups again.
Speeds seem to be around 2.5GB/minute – which again still seems slow, however multicasting works as it did before, which is absolutely fine. We recently had some switch upgrades to Cisco 3850s, which should make all links 1gbps now. More testing of our other labs will take place over the coming weeks. But as far as FOG is concerned, this is likely to be the last post on FOG for a while (or, at least, it should be). The issue to cover now, will be snapins.
FOG versus Desktop Management software
Currently, our base image for Windows 7 has all of our software installed. This weighs in at around 90GB and means that, once deployed, a computer has everything it needs for every possible lesson taught in our labs. Additionally, once completed, every PC will be configured the same; with ZenWorks, our University would deploy a basic copy of Windows XP and the packages for a given lab would be added and downloaded.
The problems we faced were that we wanted to be able to use Windows 7, about 10% of all PCs would fail to image and – even the ones that did image – were inconsistent in which packages they had managed to receive. The University now uses LANDesk, Windows 7 and has better infrastructure, but our department still is using our own system – FOG – and we have been quite happy with the process that we have in place.
One problem with our method is that the image is big. Its HUGE. A very basic, cut-down Windows 7 image is a fraction of the size – but this means having to deploy all the software to each machine which, really, works out as no quicker (it will likely take longer, too, as a multicast of a 90GB image is just as quick for potentially every PC in our labs as a single PC – the alternative is to transmit the same packages individually to PCs). So this was our logic behind making a single large image. But aside from the upload and download times for the image, the real issue is changes that might be made to the systems; this means adding, removing or changing software.
Zenworks had a bunch of management features and LANDesk seems to have quite a number, too. FOG, on the other hand, seems to really focus on imaging and not much more; there are some things that are useful, such as remote initiation of system reimaging, Wake On Lan, remote virus scanning, memory testing, user login recording and system inventorying – but it isn’t really a management tool to the level LANDesk is, which is something we may have to address in future. However, FOG does have a service component present on all client machines that checks in with the FOG server every so often to check if it has any tasks active. This FOG client service has modules that will do things such as hostname changing and active domain registration, logging on and logging off, printer management and so on. This is expandable by simply adding our own modules that can be written in C# (so we could replicate lots of managment functionality if we could write it, for example).
However, the one really cool thing that I hadn’t really explored until now is the ability to deploy packages through “snapins”. Properly managed, snapins can accomplish a few things that we need to be able to do; remote deployment, removal and uninstallation of software installations on multiple PCs and being able to run commands remotely on systems. This means that we can now update software without having to redeploy an image or manually manage those workstations by hand (although the same changes we may make would still be replicated to the base image for updating future PCs).
Snapins with FOG
The first thing to note is, actually, I have used snapins before. However, they were just command-line .bat files which would essentially remotely initiate installers that were locally stored on PCs. One example is a Sophos package we have, which once installs, attempts to update itself. It should then restart a PC, but there needs to be a timer added. This batch file worked quite well. However, I couldn’t work out how to run an executable .MSI or .EXE by uploading it. This is where I then found this guide, which walks through how to make an snapin from start to finish using 7-ZIP SFX maker.
Essentially, however, the simplest explanation is (for SFX 3.3):
- Have every file you want in a 7zip file archive (including your batch script or cmd file or whatever)
- Open SFX maker (Probably stashed under Program Files (x86) folder) and drag and drop your .7z file onto the big empty space. Check the following:
- Dialogs->General->Tick “Extract to temporary folder”
- Dialogs->General->Tick “Delete SFX file after extraction”
- Dialogs->ExtractPath->Untick “Allow user to change path”
- Navigate to the “Tasks” tab, click the big plus sign, click “Run Program” and just add the file name of your batch script or cmd file at the end of whatever is in the %%T box (eg myfile.bat)
- Click “Make SFX”
The file will be output the same directory as the .7z file. To add the new snapin, under FOG management, click the box at the top.
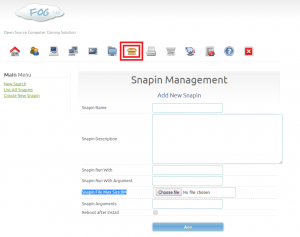
However, one important thing to note before uploading the snapin is that, by default, the snapin file size limit is 8MB, as above. Editing /etc/php5/apache2/php.ini, I changed the following values to be:
memory_limit = 2000M (2GB memory usage limit for snapins) post_max_size = 8000M upload_max_filesize = 8000M (8GB upload maximum!)

This should give us no problems with any of the packages that are bigger than 8MB. Afterwards, the web server needs to be restarted with “sudo /etc/init.d/apache2 restart” (and make sure its M in the PHP file – don’t write MB, otherwise the php file gets upset!).
After uploading the snapin to FOG, you can assign it just like an image; either to an individual host or to multiple hosts through groups. Within a host, you can actually now remove snapins much easier. You can also choose to deploy a single snapin to a host immediately or all snapins; generally, I would assign snapins to a group (such as a room where only one piece of software is licensed for) and any hosts in that would receive this software when the image is initially deployed, with the snapins then automatically deployed post-image. However, in the case of the example used here, Questionmark is a piece of software that we have, relatively late-on, been tasked with installing for another department in the University. Automation of certain uninstallations and updates should also be possible this way too – hopefully in a future update, I’ll be able to talk about making custom modules for FOG or any ways in which snapins are tweaked and deployed further.
But so far, FOG 1.2 seems to be running absolutely fine!
‹ FOG Update – Part 6 Multiple-user student webserver ›