ESX Clusterbombed – Part 1
BIG problem – our ESX cluster has fallen over. Kind of. Not entirely – but enough to be a complete pain.
The symptom – our student webserver called ‘studentnet’ (which also hosts lots of student storage) stopped working. Actually, for a while I suspected something may happen, because we were observing very high memory usage (95% memory usage on a server with ~132GB of memory?!) which was all being used up by studentnet (with high CPU usage spikes too). A student may have been running something that went nuts – but regardless, I went to log into the VM client to check what was happening. This is where it all started to go really wrong.
The vCentre host was down. But the internal wiki site we host was up. Really weird stuff. I tried to log into the individual hosts that run the VMs and could get in fine; although studentnet just wasn’t responding at all. At some point – stupidly – I decided to restart the host machines, as one wasn’t appearing to respond (it turns out later that it just was just active directory permissions that either were never set up or have somehow – at the time of writing – died a horrible death).
This was stupid because, mostly, it was un-necessary – but crucially it meant all of the VMs that *were* running were now turned off. Very bad news in one or two cases – as I will try and cover later (when I talk about turning certain servers back on) – because any servers that were running in memory now have to reload from storage.
And the storage is where the problem lies.
When my previous boss left in December, I asked him what we should do to move forward; what thing we should try and carry on working on if he was to have stayed around. He was quite focused in saying that storage is the one thing that needs attention and a proper solution for because – well – we have no backups. We have told everyone who uses studentnet this – as we have also told them that it isn’t a primary storage location in the first place (and I have a feeling many were using it for this – as well as running files directly from their user area, potentially causing lots of constant I/O activity) – but that is really of little comfort to those who were needing to submit assignments last night.
For our two ESX hosts (Dell PowerEdge R815s which have 16 CPUs and 132GB RAM each) we are running a Dell MD3000i storage array with two MD1000 enclosures connected. This is probably about 7 years old now – and although my experience with storage management like this is limited, I have a feeling that we should be looking to have at least some sort of backup, if not replacement.

Our compact ESX cluser with storage nodes
Nevertheless, performance has been ok – even if it has been sometimes intermittent. However, there is a “procedure” for re-initialising the array in the event of a power cut or if something just goes wrong – essentially disconnecting the head node (which is the MD3000i – 15 disks of slower, but big 1TB, SATA drives) and powering it off, before then power off the MD1000 enclosures (each has 15 disks of faster, but smaller 300GB, SAS drives). I should really read up more about uSATA and SAS drives – but for now, the main thing is to get things running again. Before doing this, you should really power off all VMs as this stops I/O activity – but the VM will still keep running (just without the ability to write back to disk) even if you disconnect the hosts from the storage array.
I realised after the hosts had been restarted (as I had stupidly done earlier) where the problem lay. On both hosts, several VMs failed to even be recognised – including Studentnet and frustratingly, the vCentre machine (seriously, why is this running as a virtual machine stored on the flakey storage array!!). And these happen to all be stored on our MD1000 enclosure 2.

The storage enclosures
Going back to the server room, I had a look at the lights on the disks. Several orange lights. That was probably bad. It was very bad. You probably shouldn’t do this, but I simply removed and replaced back into position the disks that had orange lights on – and several of them actually went green again. I thought that might be an improvement.

This doesn’t bode well…
And actually, it was to some degree. The first enclosure was now orange-light-free – with the main unit’s LED now showing blue and not orange. I thought this might be good. But opening Dell’s Modular Disk Storage Manager tool (useful, but it should be more visual and show more log information. Or maybe I can’t find it), showed me the true extent of the problem;
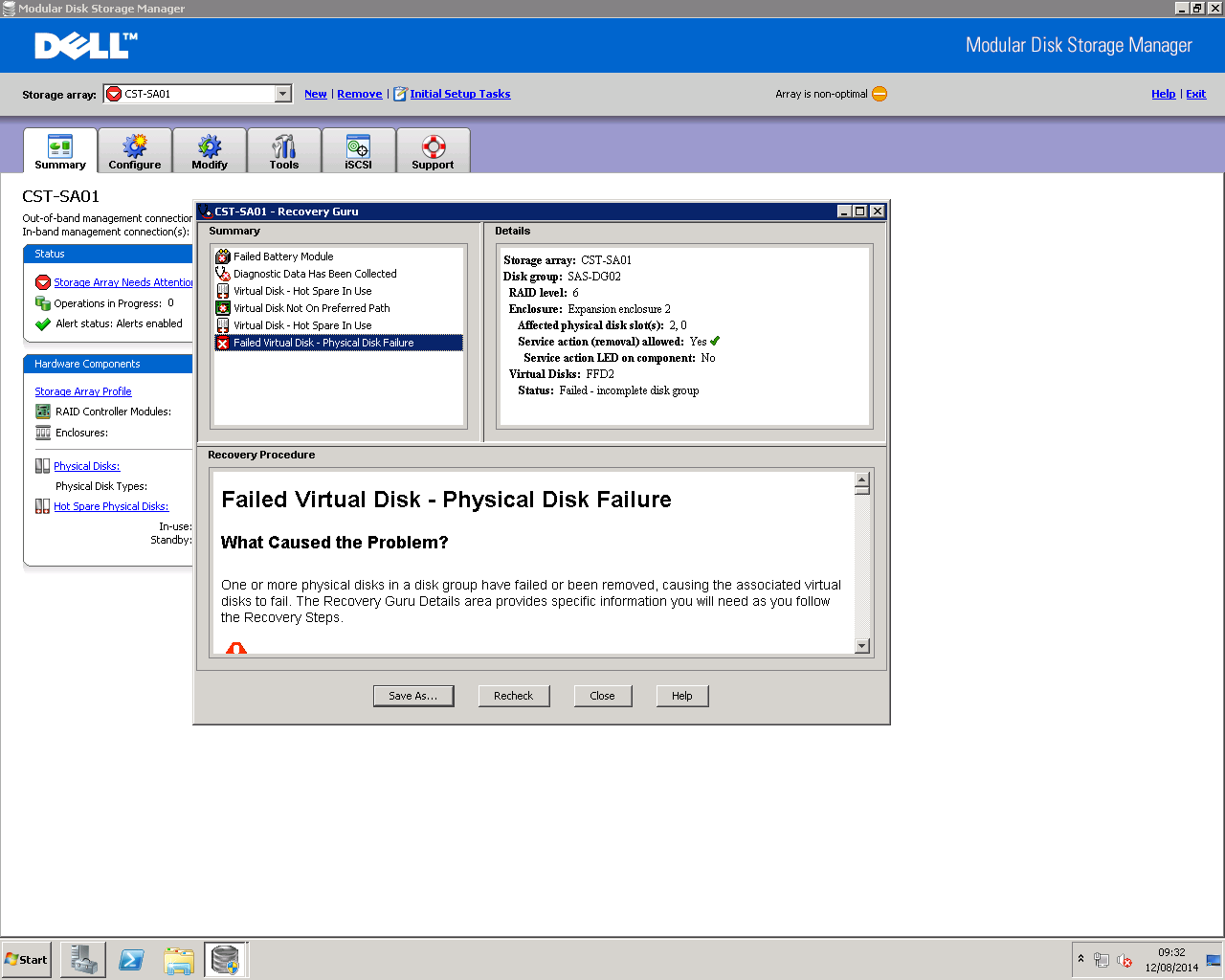
Yeah, things are pretty bad. FFD2 (the second fast enclosure) has failed. In fact, drives 0, 2, 4, 7 and 13 (which was a spare) have all failed.
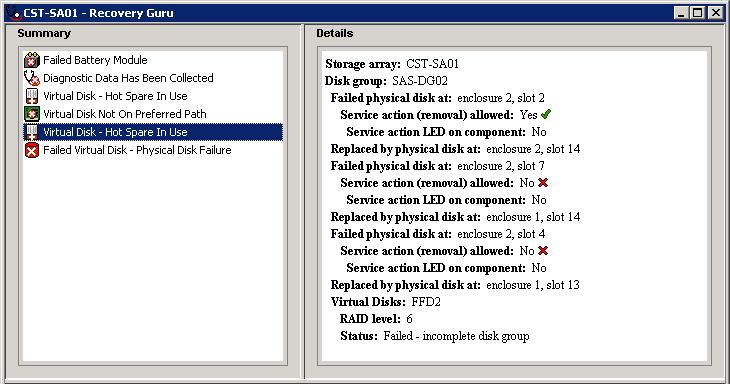
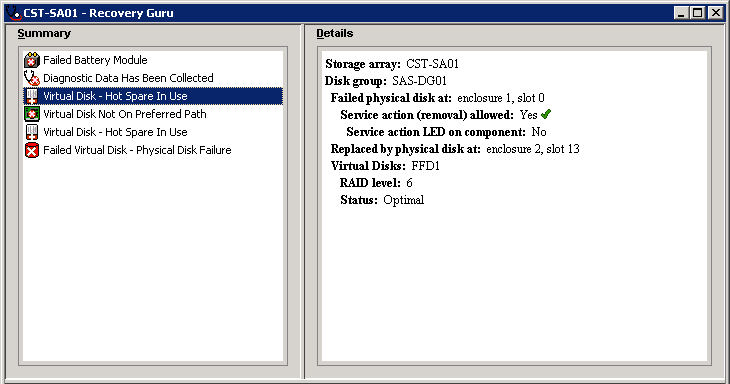
The strange thing is, though, is that even with the current replacement mapping, RAID 6 should allow for 2 failures and still be able to operate. I would have thought that means you can have six failures on one of the arrays, using four hotspares to rebuild data and accepting two drives as total failures. But again – my experience of storage management is limited and I have no clue how hotspares are actually used within a RAID scenario.

Taking out the dead drives..
The next thing I’m off to try is to restart the arrays again. This needs to be really sorted as soon as possible and the total loss of that enclosure is just not something that can happen. If hot spares fail, i’ll replace them with disks from another machine that also has 300GB 10k SAS drives in (what can go wrong?) one at a time and see what happens.
Whatever happens after this, a key thing we need to look into is buying more storage, as well as the backup and maintenance for it. And, for now, FOG has to be on hold too.
To be continued!
‹ FOG Update – Part 3 ESX Clusterbomed – Part 2 ›